
“There are only two hard things in Computer Science: cache invalidation and naming things.” - Phil Karlton
I first came across this quote about a decade ago, while I was still in college. I could easily relate to the second part about naming things but not to the first part about cache invalidation. Maybe because I did not come across that problem until then. It was not until very recently (late 2014) when I realized that the cache invalidation problem is actually much bigger than the naming problem. Maybe that’s why it’s mentioned first in that quote (maybe!).
As part of a recent project, I worked on building the data framework and the caching sub-system for a hyper-scale IoT solution. During the implementation, we came across several issues related to caching and how they impacted the integrity of the overall system. For instance, not being able to figure out which evil piece of data stayed in the cache was be a debugging nightmare. In this post, I’m sharing some of these issues and our learning from them.
The Scenario Link to heading
What we have is an Azure cloud-based system with multiple cloud services communicating with each other and the outside world while sharing an awful lot of data. We needed a distributed cache solution that could be accessed from all cloud services. And we decided to use Redis.
Side note about Redis: Redis is a high performance, in memory, data structure server (not just a key-value store). On large scale systems with lots of data calls per second, redis is just the thing you need. On average, it’s way faster than usual database systems. And the reason being, redis serves data from memory while the database systems (mostly) serve data from disk. I can write more about Redis and its performance but that’s already well documented and written (tons of articles and blogs on the net) and that’s also not the main subject of this post.
Back to the original topic of caching in our scenario, we created a simple framework using the Cache aside pattern. As per this pattern, we first try to get data from the cache and if we don’t then we get it from the primary data store. When we get it from the primary data store, we cache it as well. Next time when we need the same data then we get it from the cache. The reason we used this pattern was that most of the data in our application was changing frequently and we wanted to keep the cache updated.
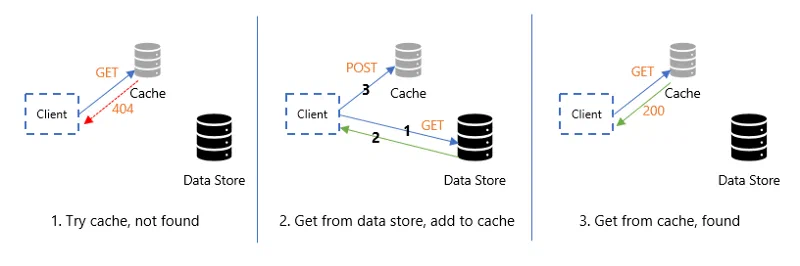
One important thing we noticed was that this pattern does not say much about cache invalidation. In a distributed environment, when the data being cached by one cloud service is accessed by another, we needed to make sure that the cache is invalidated properly.
Invalidation Link to heading
Initially, we faced a lot of issues because of data not being invalidated properly. Most importantly when transactions across services were involved. For example: if a transaction involves an update of two or more tables (data sources), the cache for those records in both tables should be invalidated, which could be tricky at times. To resolve this, we followed the repository pattern and used dedicated repositories for entities involving surrogate keys and distributed transactions. For everything else, we used a common base repository. More details about this pattern are available here.
Latency Link to heading
Another issue we faced was of latency and timeouts. These issues are not specific to caching in particular; timeouts can arise in any network-based system. Also, while using a distributed cache, latency can be our biggest enemy. Imagine a scenario when the cache server is slow (because of some reason) and is taking time to serve data. Do we want to wait for it? If yes, then for how long? For this we wanted the cache to fail fast. We decided not to wait for the cache for too long. We introduced cache operation timeouts so that we could use the primary data store if the cache was slow. If we think of mission-critical systems, this can be a defining factor. In order to respect those ever challenging SLAs, we needed to make sure we are optimizing the data access as needed.
Client Link to heading
The performance of a distributed cache also depends on how we are accessing it. In our solution we used StackExchange.Redis C# client for Redis. StackExchange.Redis is a high performance and highly configurable client and helped us in easily defining those timeout intervals and other useful settings that were specific to our scenario. We made the connection (ConnectionMultiplexer) at the start of the cloud services, using a thread-safe singleton, and reused that connection in the lifetime of the service. The ConnectionMultiplexer maintained its own heartbeat to the redis server(s) and monitored the connection. Even if the server went down and came back up, this connection remained open and helped us reuse the same object.
At a later stage, when the system grew larger, we faced repeated issues because of using a single ConnectionMultiplexer object across the service. We then created a pool of ConnectionMultiplexer objects at the service start and used them in a round-robin fashion. This helped.
Another issue we faced with the StackExchange.Redis client was intermittent timeout exceptions in case of retrieving large objects from the cache. For this, we optimized the size of data objects being retrieved from the cache.
Stale Data and Dirty Keys Link to heading
One more thing that caused issues and needed attention was dirty keys in the cache. Let’s look at it this way — what if the operation failed during cache invalidation? We tried to remove a key from the cache but we couldn’t and it stayed there. The next time we accessed that key, we got stale data from the cache. To handle this we maintained a list of dirty keys. These were the keys which couldn’t be deleted from the cache when they should have been. So, the next time if the key we were accessing was marked dirty, we would directly get it from the primary data store and the cache-aside pattern would take care of updating it in the cache. So many checks seem like an overhead, but they are important. We had to make a tradeoff between data integrity and the latency introduced by these dirty key checks.
That’s it. These were the some of the issues which we faced with distributed caching in our cloud application. Addressing these issues was a good learning.