
For the last few months, I have been looking into the actual usage of AI in software engineering and, most importantly, in enterprise setups. And to understand it better, I wanted to know what’s happening under the hood. Since late 2022, when ChatGPT went mainstream, the AI conversation has been dominated by generative AI, specifically large language models (LLMs). So, I’ve been trying to understand how LLMs work. Not from a machine learning book’s perspective or from a layman user’s perspective, but from a systems engineer’s perspective.
Having been building software for more than a decade and a half, I like to understand things in terms of what is happening at runtime. So, about LLMs, some basic questions came to my mind: When you send a prompt to an AI model, what happens behind the scenes? Does it query something? Is there a database somewhere? Is there a cache? What’s the actual execution path? I think I have somewhat figured it out, and I’m writing that down in this blog post.
In the context of this blog post, when I say LLMs, I am talking about base models only. We are not talking about products like ChatGPT or Claude. These are applications with APIs, tools, context cache, etc., and the AI model is at the core of them. We are talking only about that core stuff here.
A quick note: this post looks at LLMs from a high-level systems perspective. I am intentionally skipping the nuances of attention mechanisms, activation functions, and layer internals. The goal here is to build a useful mental model for how inference works at runtime, not to write an ML textbook.
At the core, an AI model is just a collection of numbers loaded in the GPU’s memory. It’s like a large matrix. These numbers are called weights and biases. These are also called the parameters of the model. Think of these as configurations, except instead of a few hundred settings, you have billions of them in AI models, and they were learned from training data, not set by an admin. You must have seen several model releases with the number of parameters mentioned, like 7 billion, 70 billion, 400 billion, and so on.
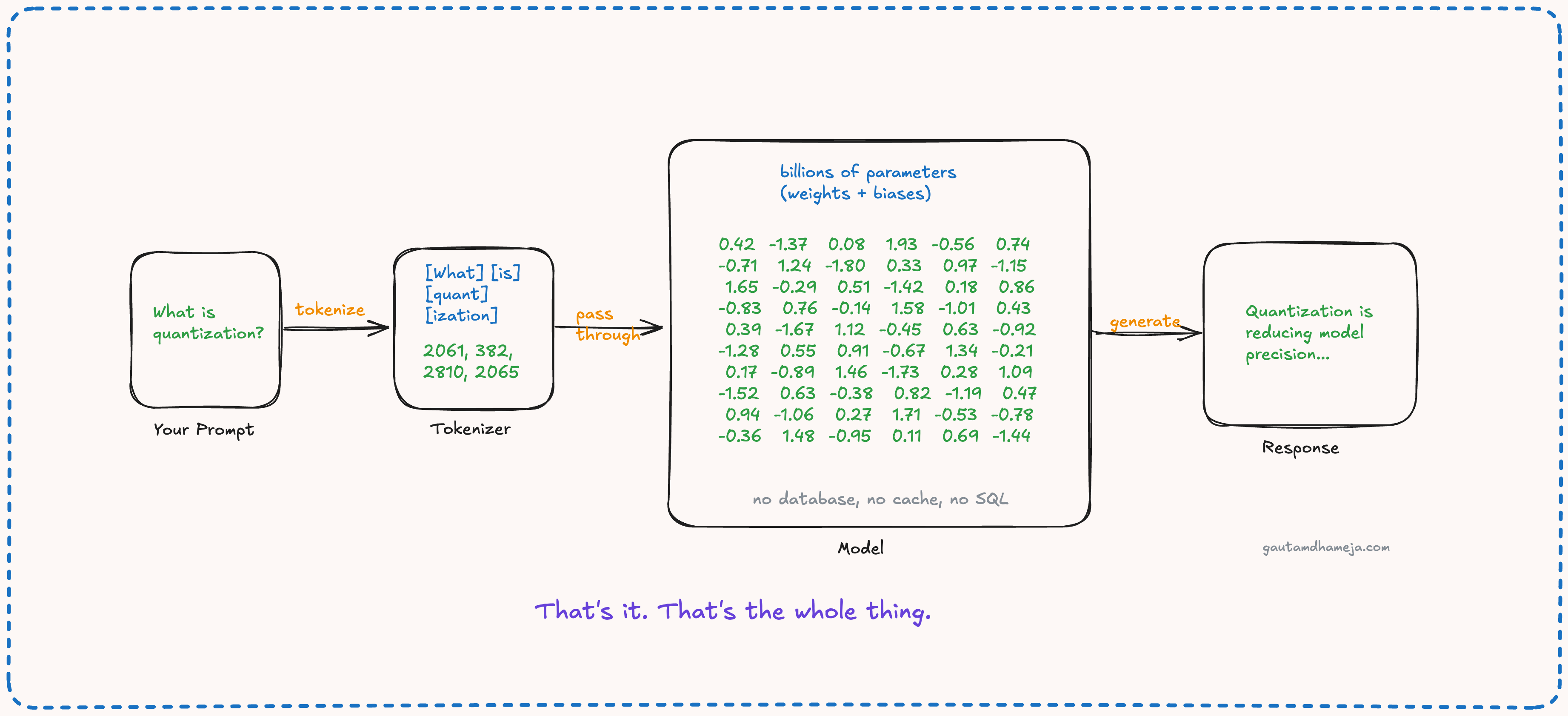
When you send a prompt to an LLM, first the prompt is tokenized. Then these tokens are fed to the model. Each token maps to a high-dimensional vector via an embedding table. The model doesn’t see words. It sees vectors in a learned representation space. Then your prompt tokens are multiplied by the weights of the model in a particular sequential order, layer by layer. The internal architecture of these layers could be a subject for a future post. For now, let’s focus on the end-to-end flow.
Generative AI models are auto-regressive. They generate one token at a time. Each prediction is conditioned on the full sequence so far. It is worth noting that AI inference is a stateless forward pass. No session, no persistence, no state between calls. The computation scales with sequence length and model size, and the entire model must be loaded into GPU memory before a single token can be generated.
The forward pass first computes a weighted sum of the inputs, followed by a bias addition. The model is then able to predict the next token based on the outcome of this mathematical operation. Finally, because this prediction also happens in tokens, it is converted back into our natural language. That is how the result is presented to us.
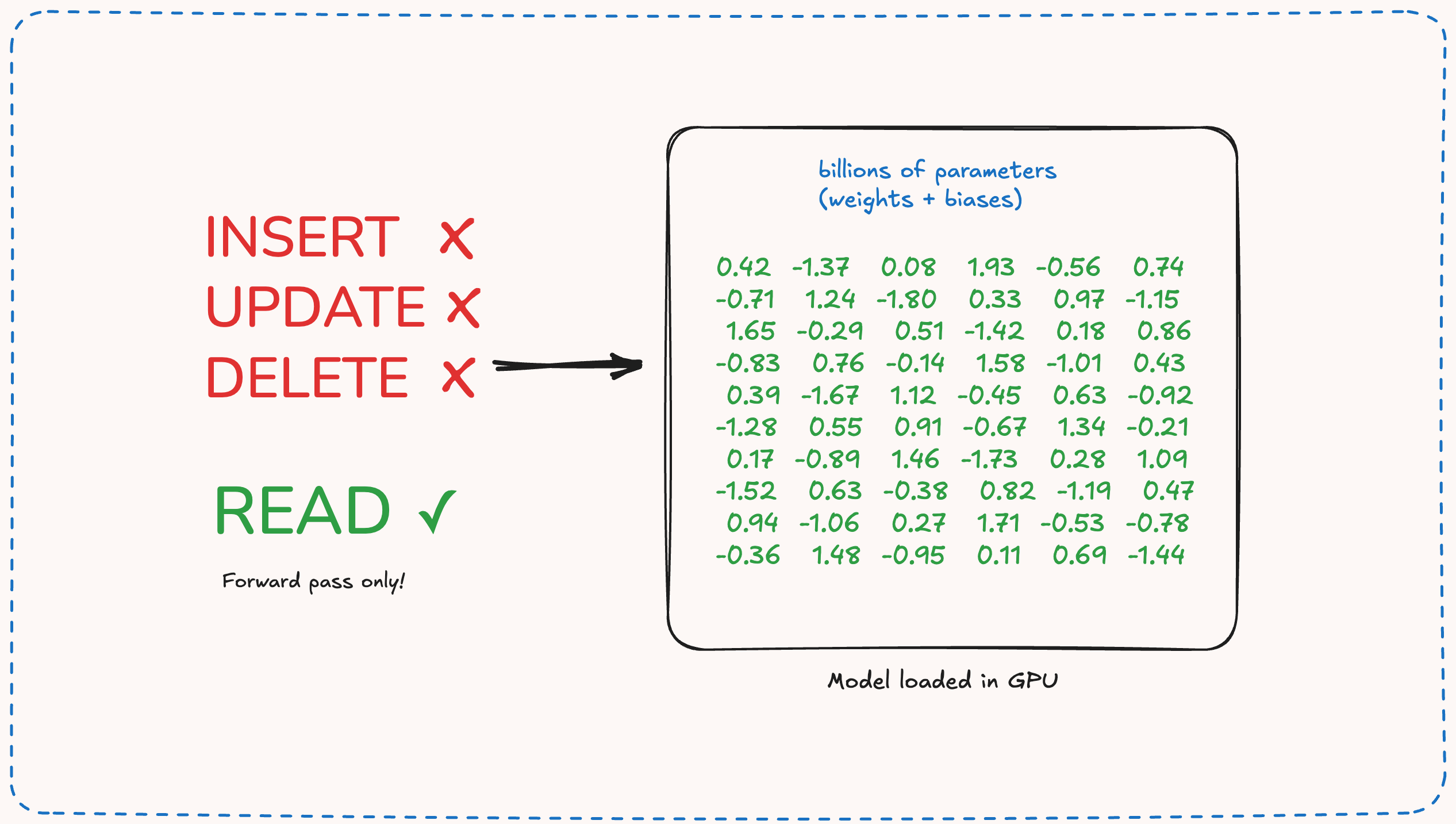
Another thing to note is that once the model is trained, its weights are set in stone. They cannot be changed unless you retrain or fine-tune the model. Once the model is loaded into your GPU’s memory, you cannot make any changes there. You cannot insert a new record, you cannot update or delete a row.
And these weights of the model are trained using public data up to a particular date. The model has no knowledge of anything that happened after that cut-off date or any private data of yours. And this is why, when the base model capabilities are not enough, when you need access to private or recent data, things like RAG, tools, and MCP all come into the picture.
For software engineers and engineering leaders primarily thinking in systems, this mental model matters. This gives us an interesting insight that the model’s quality mostly depends on how its parameters were trained and not on what data it can access at runtime. The numbers alone tell you very little. When a vendor quotes parameter counts, ask what those parameters were trained on and for what domain, and whether that domain matches yours.