
Traditional distributed systems and AI agents have a lot in common, primarily from the architecture perspective. In this post, I am examining the architecture patterns between the two and drawing out the similarities and differences. This is rather high level, but it aims to give a clear perspective on how to think about AI agents if you already know how to build distributed systems.
Traditional Distributed Systems Link to heading
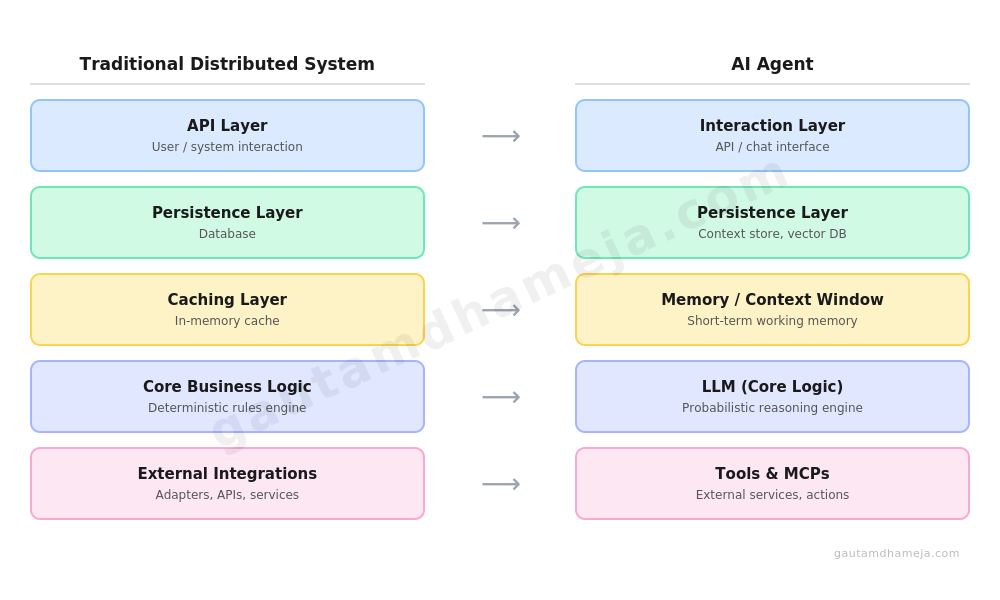
When we build a traditional distributed system, let’s say a set of microservices integrating with external systems, here is how it looks:
- API layer that is responsible for user interaction
- Persistence layer, a database
- Caching layer
- Core business logic
- Integrations, adapters, and logic for integrating with external systems
AI Agents Link to heading
Now let’s look at the architecture of an AI agent, for example.
- Interaction layer, which is the Agent API
- Persistence layer for context and memory
- Short term memory and context window management
- External integrations with tools and MCPs
- The core logic, which comes from LLM’s reasoning
The main difference is that you do not write the business logic explicitly as a condition/rule engine; you write a prompt, and then the LLM does the job for thinking, reasoning, and getting you the output. Link to heading
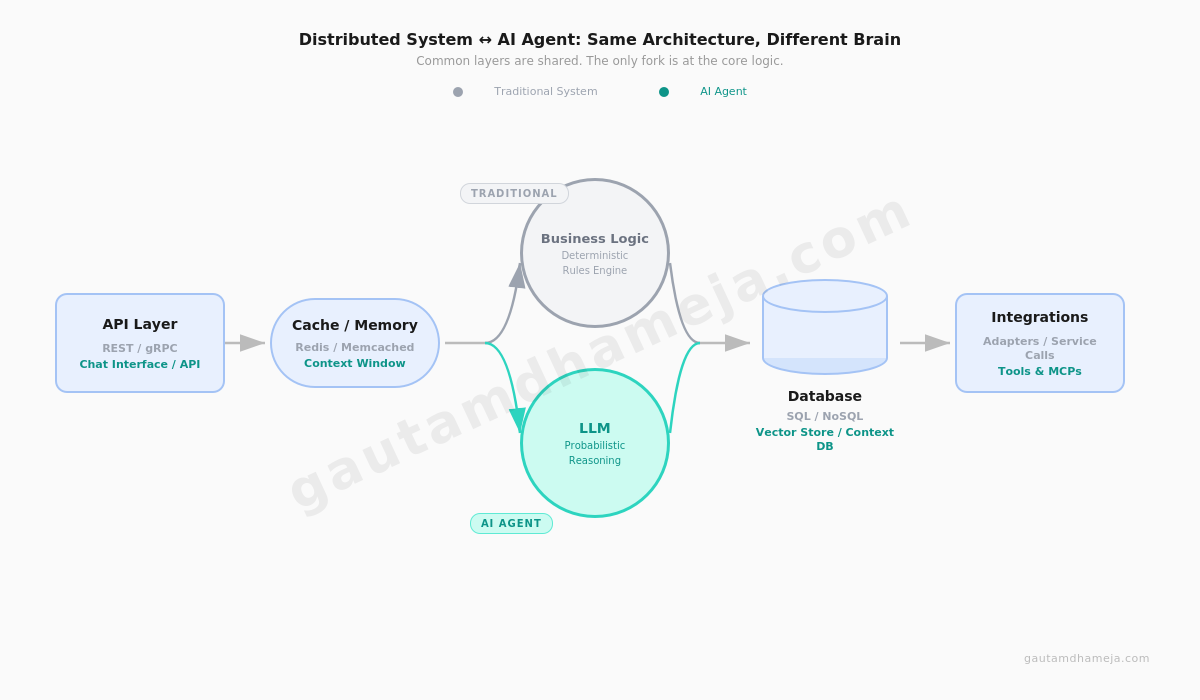
If you are a traditional distributed systems developer, you already know how to build AI agents. All you have to do is understand the fundamentals of how this reasoning based business logic or the LLM is different from rules based logic code. Let’s dig a bit more.
The Brain Link to heading
The business logic of a traditional distributed system is mostly deterministic. You give an input, you receive an output. You can unit test it, and it becomes the law of the system. The logic of an AI agent, which depends on an LLM it’s using, could be probabilistic (depending on the temperature and top-p configurations). When you give it an input, the LLM’s reasoning is deterministic, but the output generation is probabilistic by design. This non-determinism is a feature, not a bug. It makes the system cover broader user inputs. But it also means you cannot test it using traditional means, you need specialized frameworks. You have to build guardrails, tighten prompts, enforce structured outputs, and set up evaluation loops.
Orchestration Link to heading
Another parallel worth drawing is the orchestration layer. In distributed systems, you have things like saga patterns, event-driven workflows, and message queues. In agents, the equivalent is the planning and reasoning loop, how the agent decides which tool to call and in what order.
The Bottom Line Link to heading
Now, for traditional distributed systems developers, most of these architecture and design principles are familiar: how to think about latency, fault tolerance, retry strategies, API design, data consistency, and scaling. On the other hand, context window management, token-based cost management, hallucination detection and mitigation have no clean equivalent in traditional systems, so these are some of the things you have to learn.
So, it seems most developers don’t have to start from scratch. There is so much that you already know, and you can bring over to AI agent development territory. You are not learning a new field altogether, but just adding a new variable in what you already know.
PS: This post was first published as an X article, here.