
What are the chances that you will get the same output from an LLM on the same query across several runs? For the last few days, I have been wondering what is the level of determinism in an LLM’s output. What are the chances that it will give you the exact same answer every single time? This is extremely critical for use cases where decisions are based on pre-defined rules, and rules could be augmented using LLM reasoning. If the decisions are not deterministic, then the same input could be treated differently and that’s not a good thing.
So let’s start from the basics. An LLM is primarily a collection of numbers, and these numbers are the weights and biases. Unless you fine-tune or retrain a model, these weights and biases are fixed. That’s what the model training gets you.
Now, when you run the model, these fixed numbers are loaded in the GPU memory as a large matrix. When you send your query, that also gets tokenized deterministically into fixed token ids and embedding vectors. When you multiply these vectors with fixed model weights, you will get fixed results (apart from the effects of floating point mathematics). The matrix multiplication produces a set of logits, which are raw scores for every token in the model’s vocabulary. Then the softmax function is applied to the logits to create a probability distribution of possible next tokens. So far, everything looks deterministic. Then what’s the catch?
From this probability distribution, the LLM has to choose the next token to predict based on certain parameters, and that is where it gets interesting. These parameters are:
- Temperature
- Top-K
- Top-P
If temperature is 0, the LLM will pick the token with the maximum probability, and it will be added to the input, and the process will continue again.
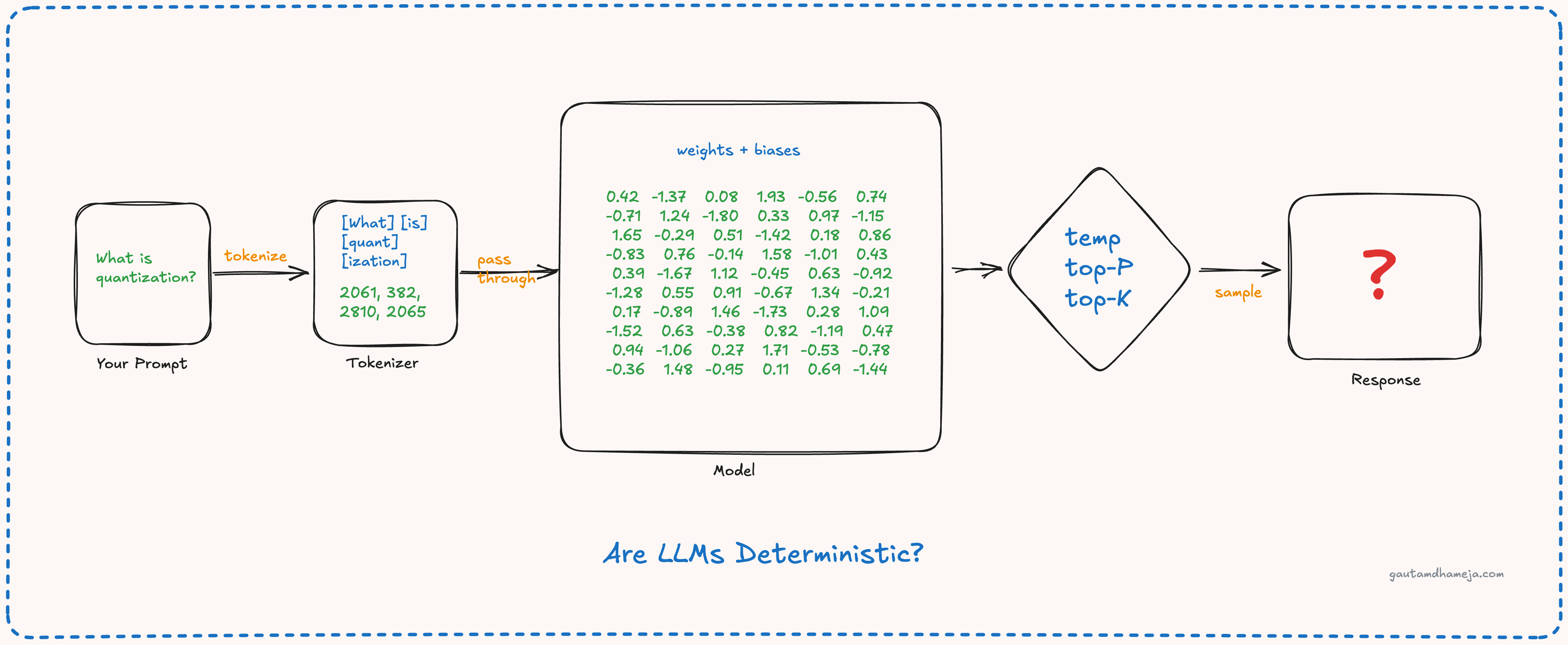
If the temperature is other than 0, all the logits are divided by the temperature value, and then the softmax function is reapplied. A lower temperature creates a more peaked distribution, while a higher temperature creates a flattened distribution. The system then does a random sampling among these tokens after applying the temperature values, and the next token is predicted.
Top K basically means you zero out everything except the top K tokens after adjusting the temperature, and re-normalize so that the remaining probabilities sum to 1, and then you sample from them.
And in top P, instead of a fixed count, you sort the tokens by probability from highest to lowest and take the smallest set of tokens with cumulative probability P, and then sample from that set.
So how does this affect use cases? When you set the temperature to 0, other params like top P, top K, random selection do not matter. The model will predict the exact same token every single time. There is a problem: this will make the model boring and predictable, and not creative at all. We will not be able to utilize the creativity and intelligence part of the model; it will become like a rule engine.
On the other hand, if we have large temperature values, the model can become completely reckless and could predict nonsense. That will also not help in any use cases. It will make the model unreliable.
Hence, it is extremely important to understand what we are building for and what are the optimal temperature and top K/P values for that particular scenario. If we are looking at business-critical operations within enterprises, lower temperatures are good, but not so low; 0 to 0.2 is a good limit for that. For use cases where the model needs to communicate with the user (e.g. reporting and analysis), slightly higher temperatures (0.5 to 0.7) would make more sense. For designing and other creative use cases, higher temperatures (0.8 to 1.2) could be more useful, because then you are able to utilize the model effectively. Beyond 1.2, the models seem to be mostly unreliable, so far.
And at the end of the day, we should not forget that even after temperature 0 there could be a little bit more non-determinism in LLM outputs because of floating-point mathematics on different hardware. It’s always important to put some guardrails around validating the outputs and having some sort of governance around it.
Setting these model parameters should be a deliberate engineering decision based on the use case, not a default set by the model provider. Most enterprise teams never think about changing it from whatever the SDK defaults to, and that’s a missed opportunity for both quality and reliability.